
在前面从 0 到 1 搭建现代前端项目那篇文章中,我们频繁看到一个命令:npm run dev 或者 npm install,那么 npm 到底是什么呢?同时,在平时的开发中,我们可能也会有以下疑问:如果我们项目依赖 A 和 B,并且 A 也依赖 B,那么 B 会被重复下载吗?为什么相同的 package.json 文件,不同开发者进行安装,最后依赖的版本会不同呢?在代码合并的时候,lock文件发生冲突了怎么办?lock 文件需要提交到远端吗?
至于这些问题的答案,相信你掌握了 npm 的安装机制之后就都清楚了。下面我们就来详细讲解。
# npm 简介
关于 npm,其官网原文是这么解释的:
npm is the world’s largest software registry. Open source developers from every continent use npm to share and borrow packages, and many organizations use npm to manage private development as well.
npm(Node Package Manager, node 的包管理器),是 node 默认的、以 JavaScript 开发的基于 Node.js 的命令行工具,本身也是 node 的一个包。
你可以这样简单来理解:npm 是一个存储前端代码的大型仓库,发布者可以将自己的代码在仓库中发布,同时使用者也可以从仓库 clone 项目到本地,通过这样的方式,实现代码的共享。
那 npm 是怎么发展起来的呢?
你可以试想一下在最初的 JQuery 时代,如果想要使用 JQuery 及其插件的话,那么需要怎么操作呢?
- 去 JQuery 官网上下载 JQuery 源码或者找一个 CDN 地址。
- 去 BootStrap 官网下载 BootStrap 源码或者找一个 CDN 地址。
- 如果想要使用某一个插件,比如轮播图 Swiper,那么就需要开发者将源代码上传到服务器上,使用者通过 CDN 地址获取源代码。
现代的前端开发,已经不再是写一两个浏览器页面或者特效就可以的了。现在的前端已经有了开发大型项目的能力。那么肯定会涉及到和他人的合作,需要引入一些开源框架、工具、团队内共用的模块。一个成熟的前端大型项目,可能要引入几十个不同的依赖,那么每一个依赖都需要自己去找 CDN 资源或者去网站上下载源码,想想就觉得十分麻烦呢!懒惰使人进步,推动科技发展,就有那么一个比较“懒”的伟大的程序小哥哥 Isaac Z. Schlueter ,提出可以将这些代码集中到一起管理。于是,npm 的雏形就诞生了。
那么 npm 后续又是如何快速地发展壮大呢?这还要归功于 Node.js 的发展。因为在 Node.js 的初期刚好缺少一个包管理工具,这不恰好是 npm 的主要功能吗?所以,Node.js 就和 npm 合作,在 Node.js 中内置 npm。随着 Node.js 的大火,作为其包管理工具的 npm 也就跟着发展起来了。
那么在有了 npm 之后,又是怎么安装项目中的依赖呢?我们只需要使用一个安装命令 npm install package-name,npm 就会帮你将源码自动下载到 node_modules 中。
也就是说,只要知道安装包的名字,然后只用一行命令就可以下载源码,这是不是方便了不少呢?(^▽^)
# npm 安装流程
前面我们只是介绍了 npm install 是用来安装依赖的,下面再讲一下它到底是怎么安装的以及一些具体的安装细节。
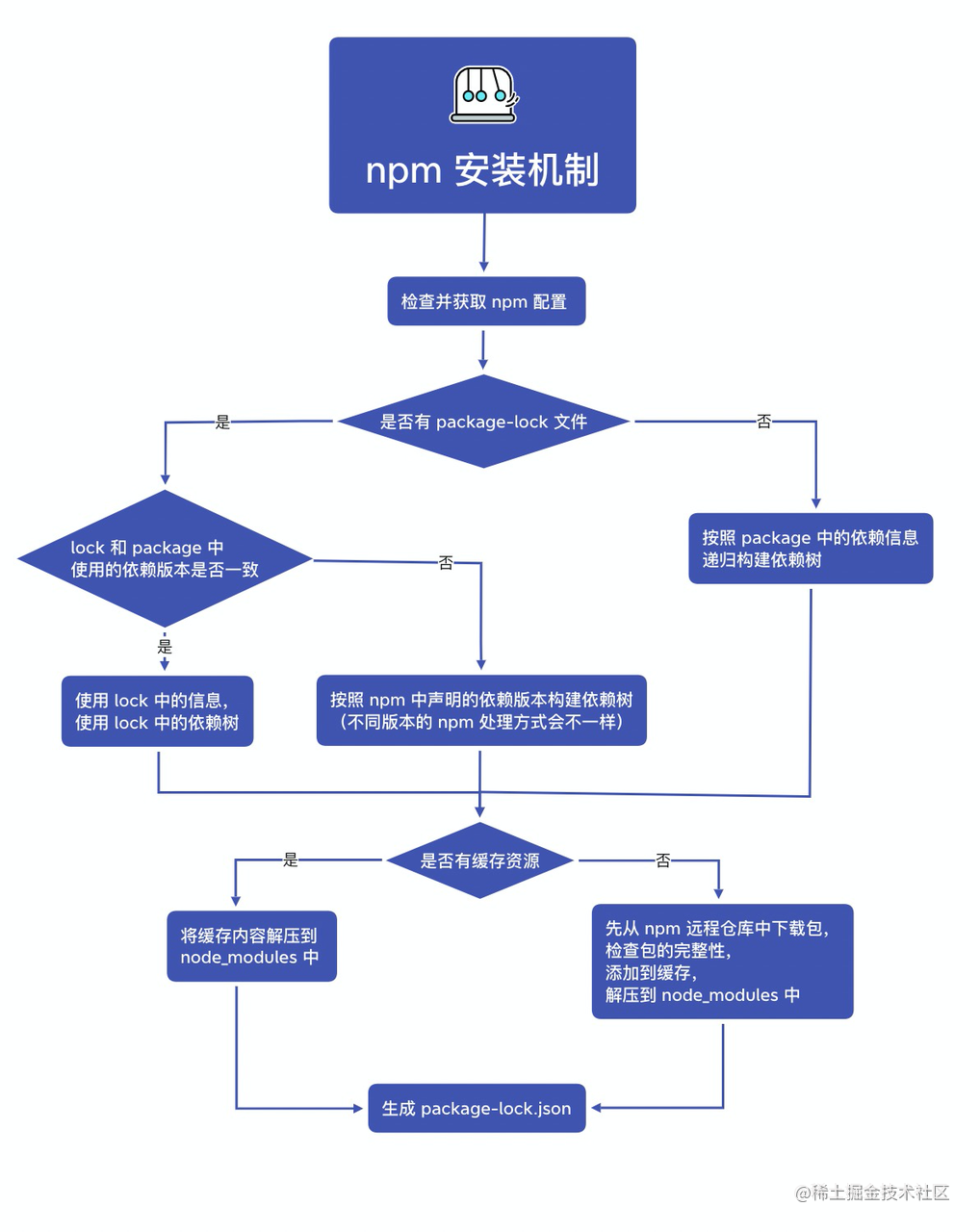
第一步:执行安装命令之后,npm 首先会去查找 npm 的配置信息。 其中,我们最熟悉的就是安装时候的源信息。npm 会在项目中查找是否有 .npmrc 文件,没有的话会再检查全局配置的 .npmrc ,还没有的话就会使用 npm 内置的 .npmrc 文件。
第二步:获取完配置文件之后,就会构建依赖树。 首先会检查下项目中是否有 package-lock.json 🔐文件:存在 lock 文件的话,会判断 lock 文件和 package.json 中使用的依赖版本是否一致,如果一致的话就使用 lock 中的信息,反之就会使用 npm 中的信息;那如果没有 lock 文件的话,就会直接使用 package.json 中的信息生成依赖树。(具体是怎么生成依赖树的呢?下面会详细介绍。)
第三步:在有了依赖树之后,就可以根据依赖树下载完整的依赖资源。 在下载之前,会先检查下是否有缓存资源,如果存在缓存资源的话,那么直接将缓存资源解压到 node_modules 中。如果没有缓存资源,那么会先将 npm 远程仓库中的包下载至本地,然后会进行包的完整性校验,校验通过后将其添加的缓存中并解压到 node_modules 中。
npm 默认不会将依赖安装到全局,只会安装到当前的路径下,这样设计是为了不同的项目之间进行依赖隔离,互不影响。当然,用户也可以选择安装到全局,只需要在安装命令后带上 -g 参数即可。
第四步:会生成 package-lock.json 文件。 那么这个文件是干什么的呢?我们都知道,在 package.json 文件中,如果我们在依赖的版本号前增加 ^ 标志的话,比如 ^3.1.6 意味着安装的时候会安装 3.x.x 的大版本中最新的小版本。这样,不同的时间执行安装操作就会有不同的结果。所以 lock 这个文件会将本次安装的依赖的版本信息记录下来,在下次再安装的时候,或者其他伙伴使用该包,或者通过 CI 工具的时候,就会安装相同版本的依赖。这样就会避免 package.json 中的内容一致但是实际上安装依赖的版本不一致而造成 Bug 出现的情况。
这里我也整理出了一张流程图,你可以结合着来理解:
# 不同版本生成依赖树的区别
在上面安装流程的第二步是生成依赖树,那么具体是怎么生成的呢?这里要详细说一下,不同的版本生成依赖树的方式是有区别的,其中主要是 v2、v3 和 v5 的版本之间的区别,我们分别来看下。
# npm 2.X
在 npm 2.X 时期,还是使用的最简单的循环遍历方式,递归地下载所有的依赖包,只要有用到的依赖,都进行安装。
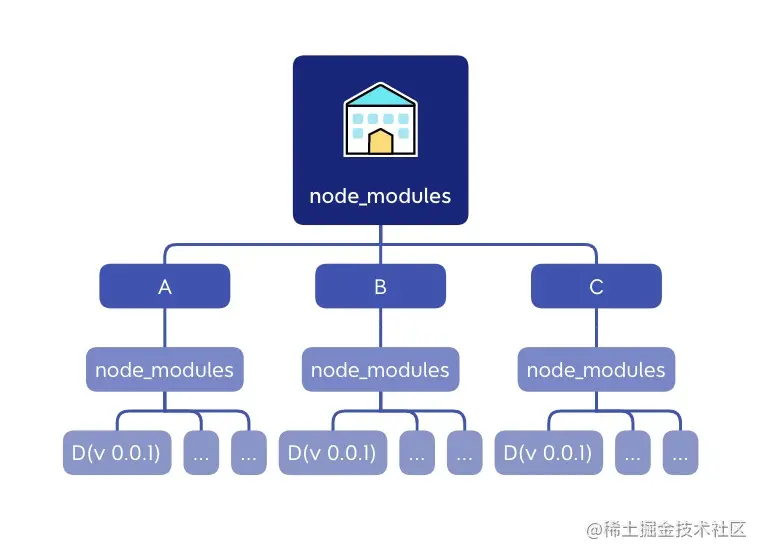
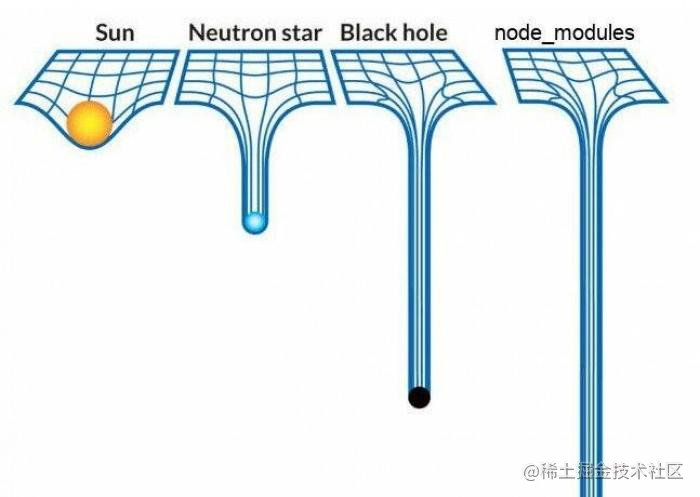
直接递归这种方式很简单,很好理解对不对?ㄟ(▔,▔)ㄏ,但是稍微想一下就知道这个有坑啊!项目之间难免有相同的依赖,然后就会有大量冗余的依赖。随着项目规模的增大,node_modules 的大小会呈指数增加。在 Windows 系统中,就有目录层级太深而导致文件路径过长报错的案例。这就是恐怖的 node_modules 黑洞(如下示意图)!
# npm 3.X
随着使用 npm 的开发人员越来越多,node_modul